ClickHouse 尝试 #
表分区 #
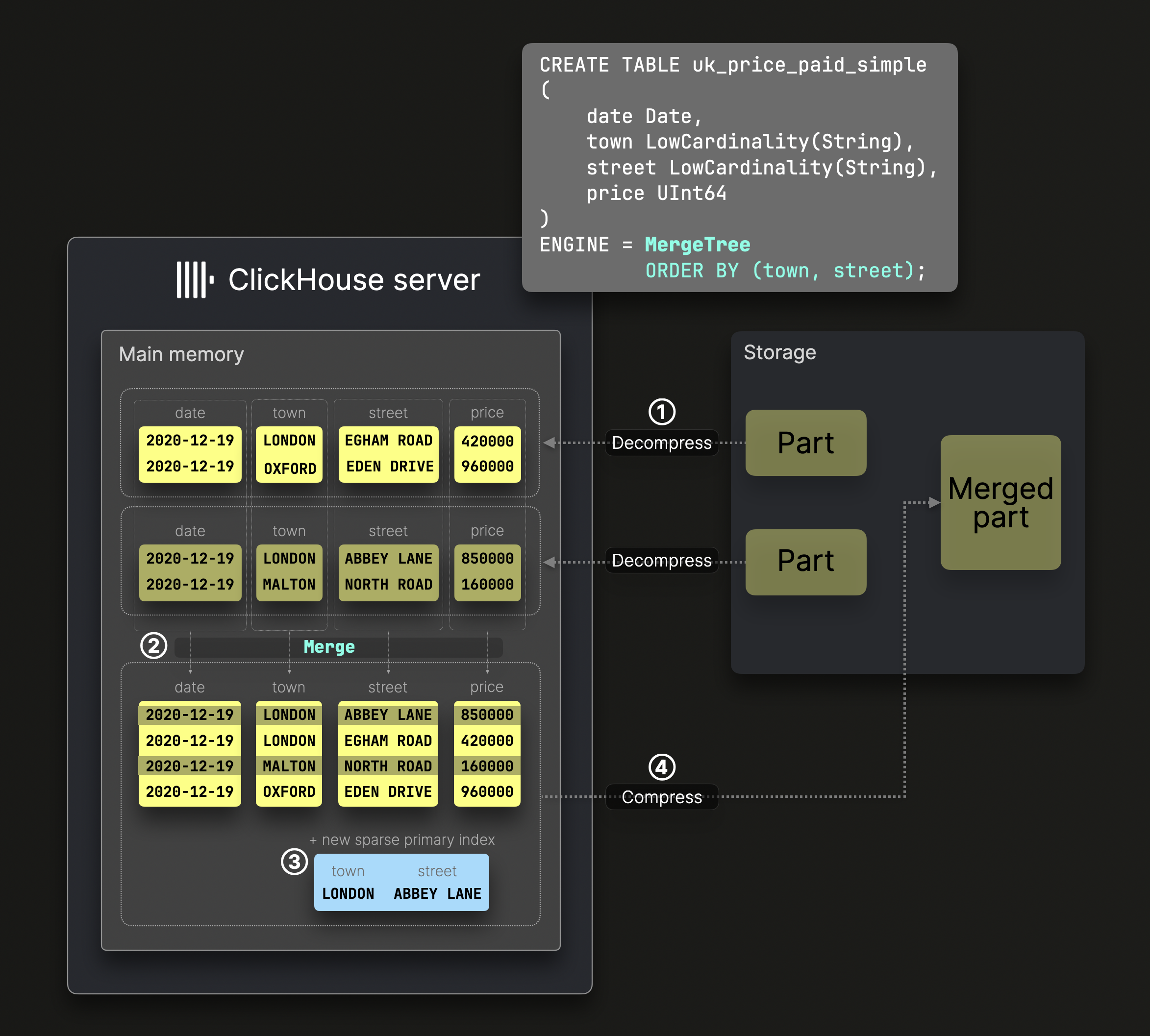
对于如下的表 在执行插入数据的时候
CREATE TABLE uk.uk_price_paid_simple
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
ORDER BY (town, street);
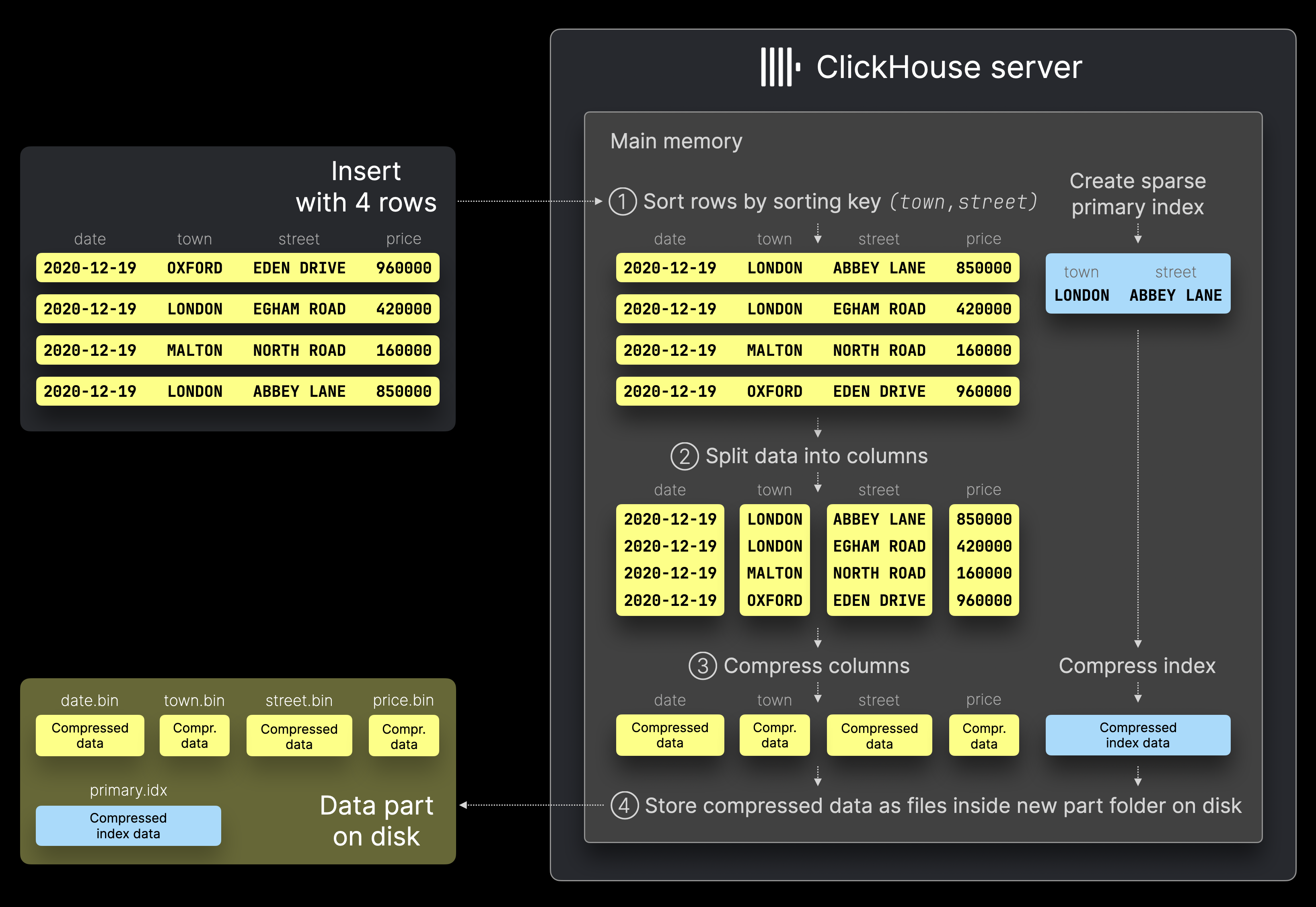
每当一组数据插入的时候 就会创建一个数据分区
他会经过如下的步骤最后存储落落盘到磁盘
- 排序 按照
order by规则进行排序 - 拆分 对排序后的结果进行拆分 成为单独的列
- 压缩数据 对每一列数据进行压缩
- 写入磁盘 写入的是数据分区
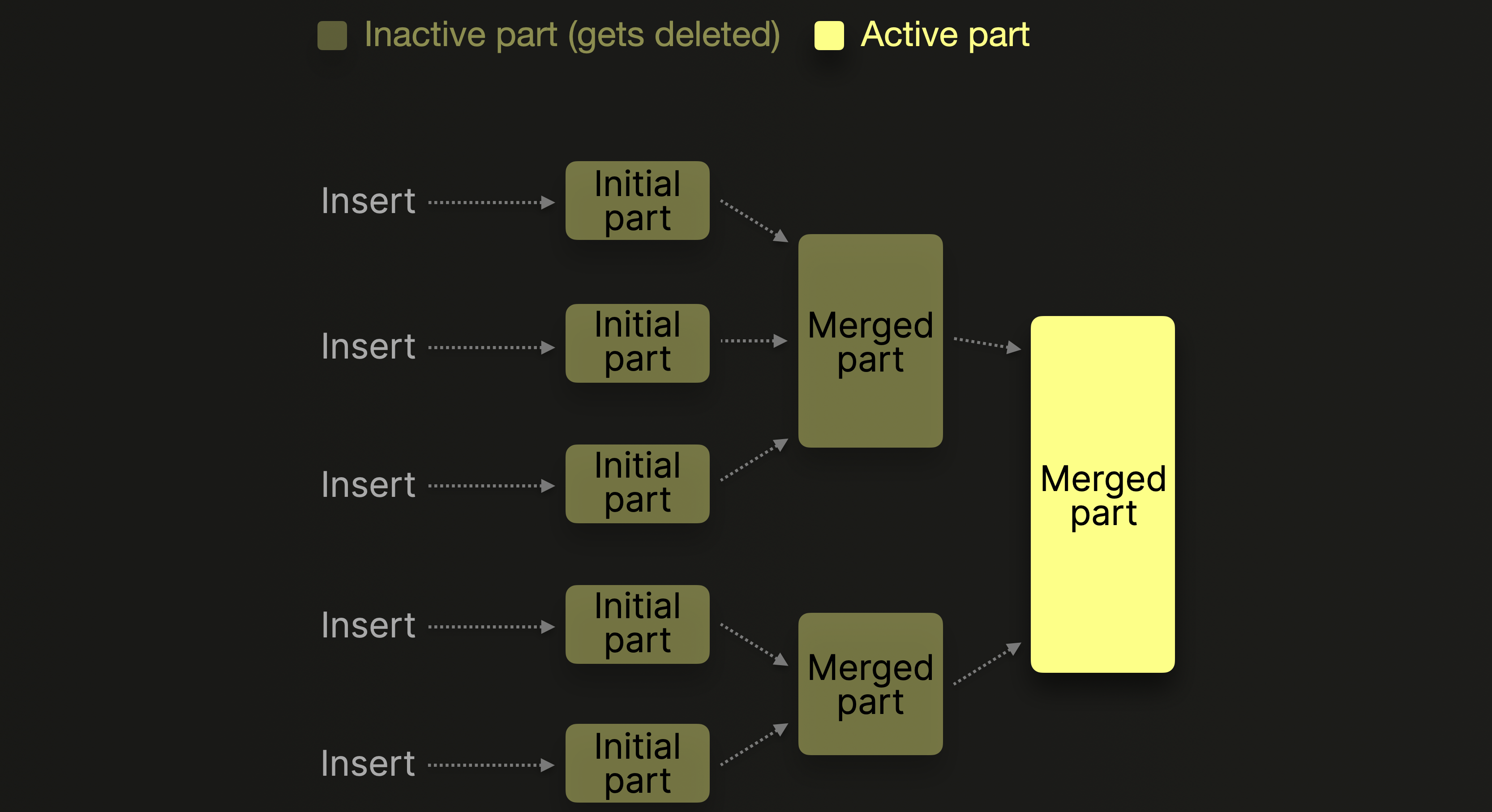
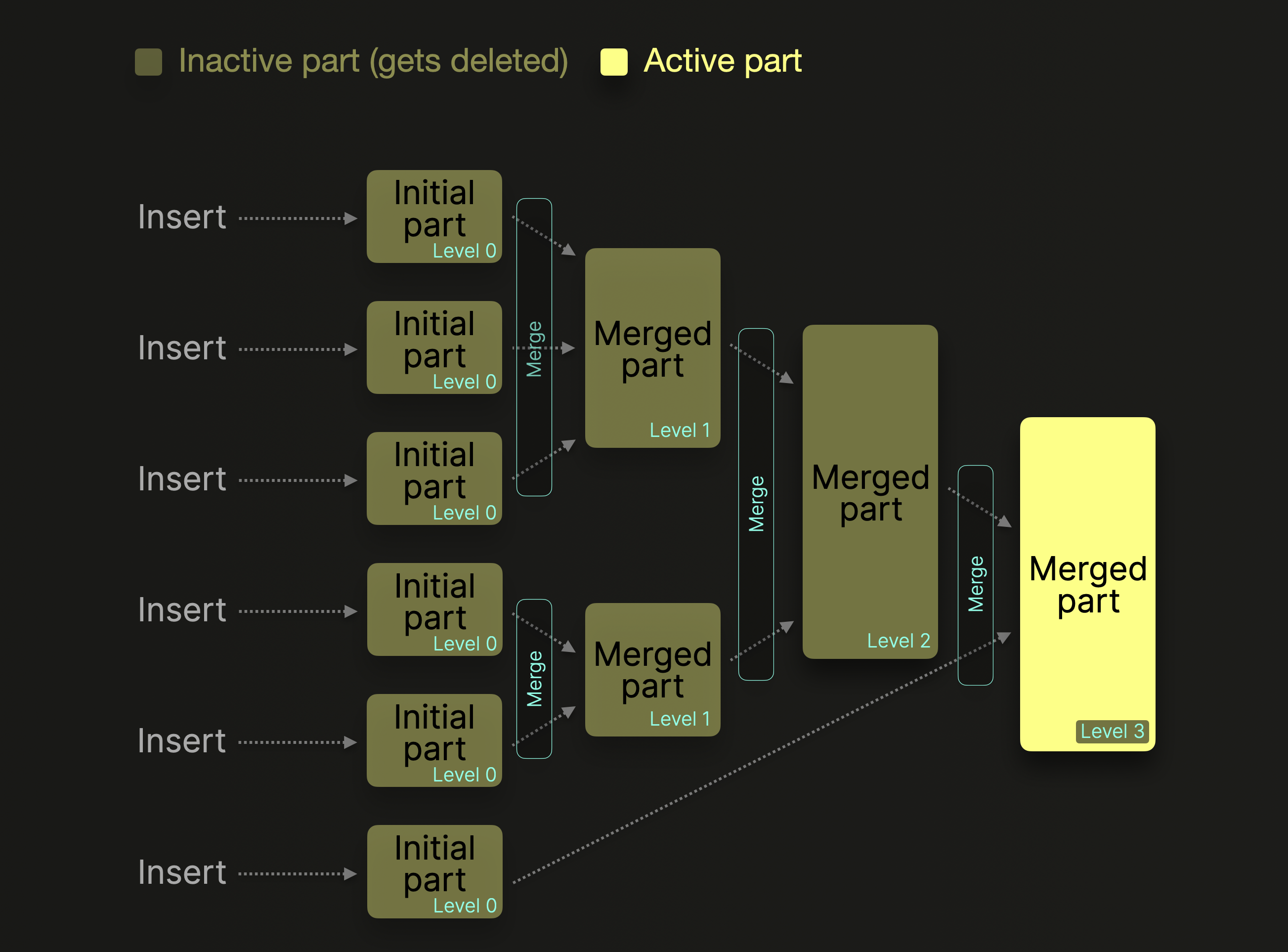
需要注意到的是 每一组数据在落盘之后 需要进行分区合并 也就是将多个分区合并成为一个较大的分区 也就是实现了ck所描述的merge操作 形成了merge后的tree
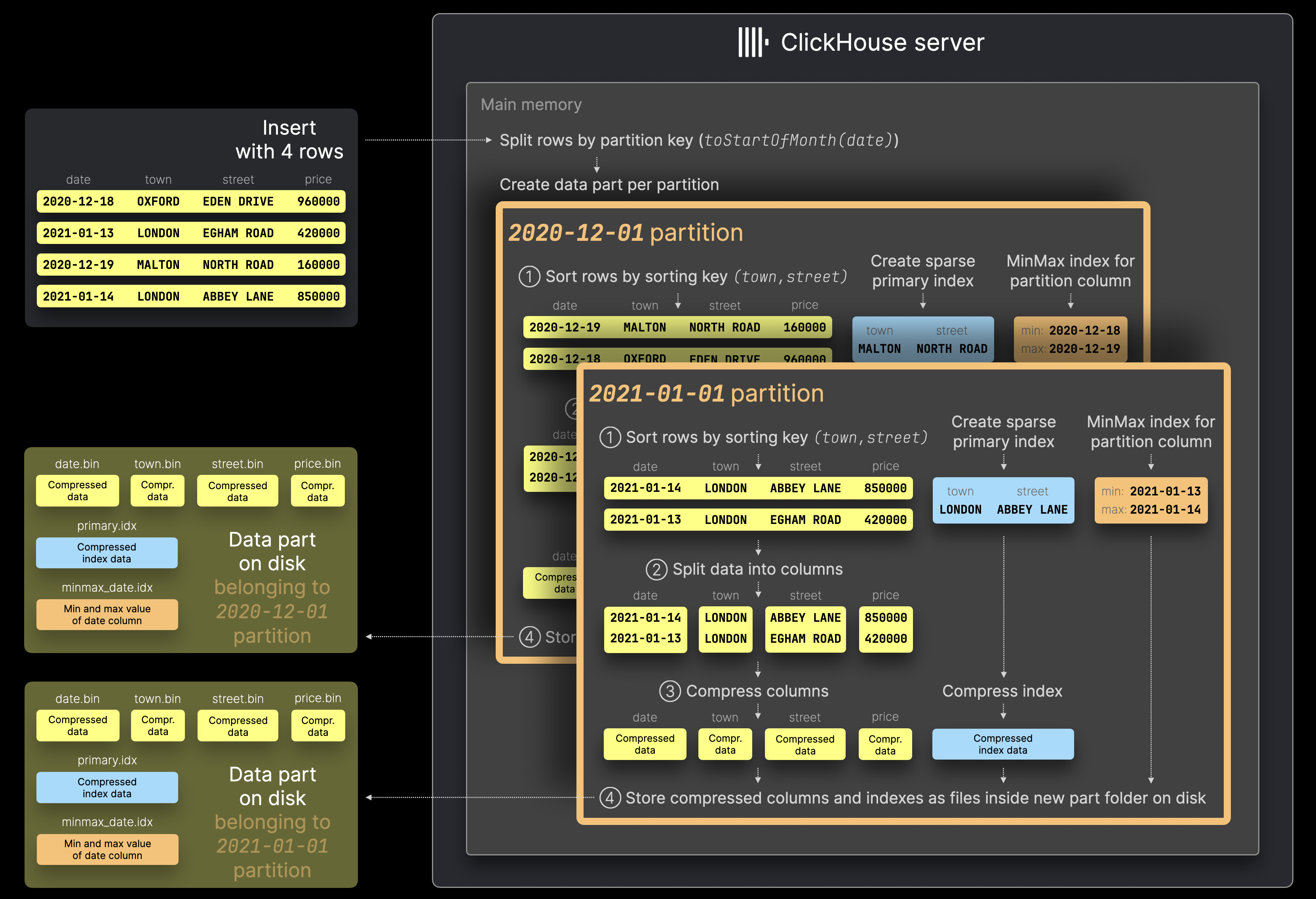
对于创建的表如果申明了分区的时候 可以定义某一行所属的分区
比如这里的sql语句 就实现了表的数据片段按照时间来进行划分
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
ORDER BY (town, street)
PARTITION BY toStartOfMonth(date);
对数据通过按照时间进行分区了之后重复上面的操作来创建新的数据片段 同时 文档提到了 不能使用高基数分区键
会导致Too Many parts 要选择合适的基数的分区键
通过表分区我们可以更好的管理数据 比如
- 自动删除数据
- 迁移到存储系统中备份
- 针对分区进行查询
这里就实现了分区修剪查询
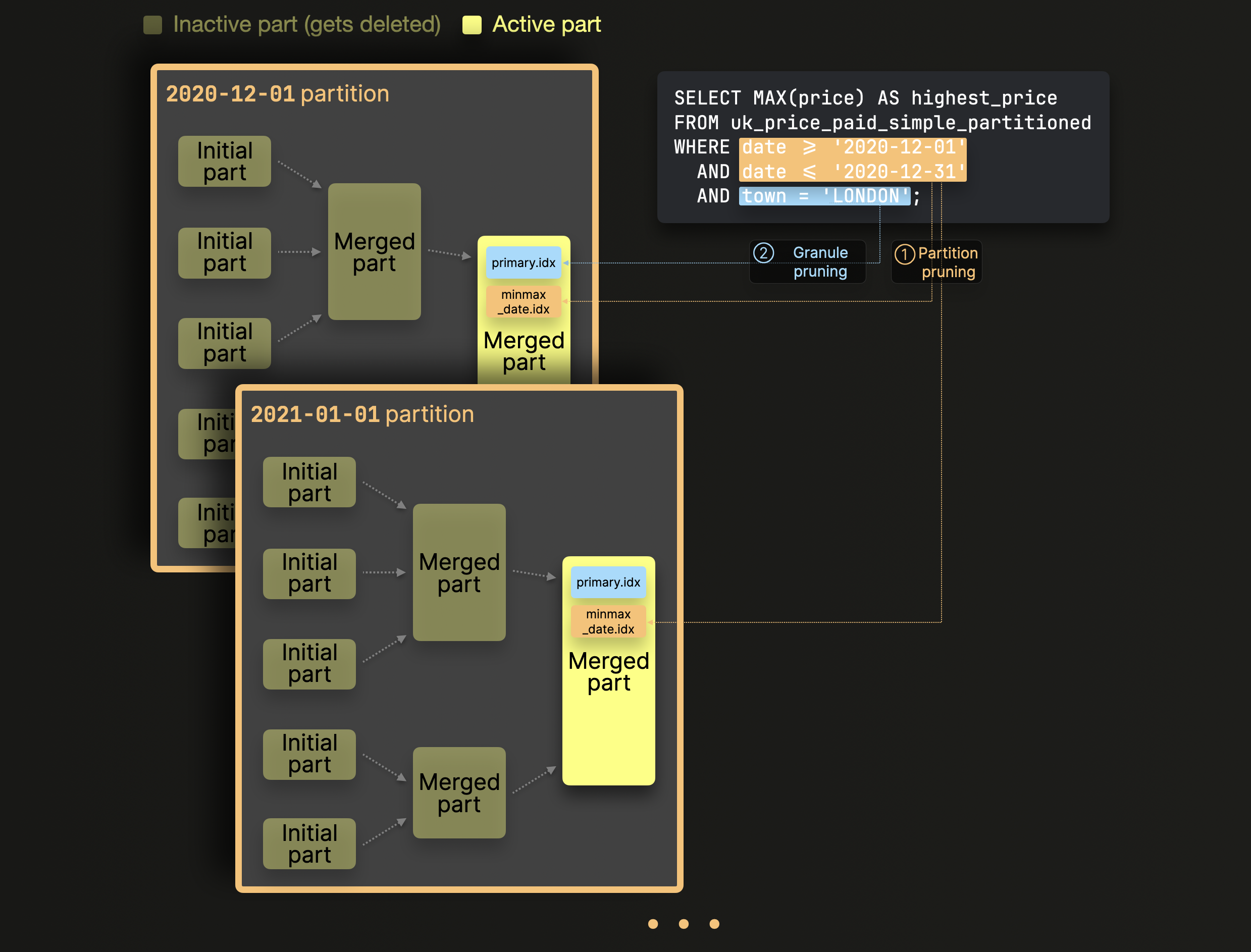
分片合并 #
分片合并通过 将较小的分片合并成为较大的分片 按照分区规则合并 形成一个合并树表
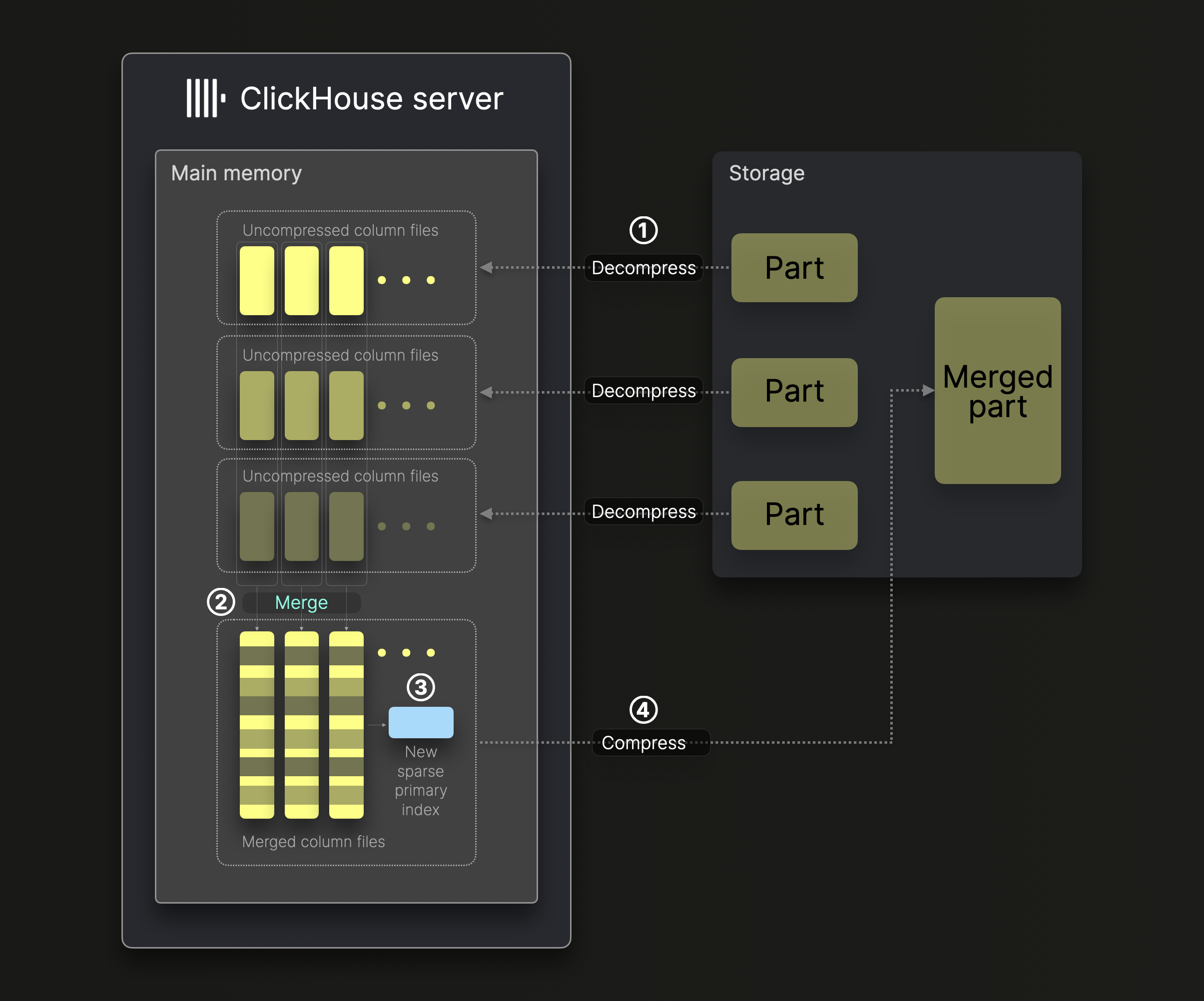
合并是由合并线程来执行的 合并线程主要决定那些分片需要合并 并将分片加载到内存中 将内存中的分片合并成较大的分片 将合并的分片写入内存 同时需要注意的是 由于不是一次性将全部的分片加载进入内存 采用的是垂直合并 默认情况不采用垂直合并
对于不同的存储引擎 采用的是不同的合并规则
-
标准合并
-
替换合并
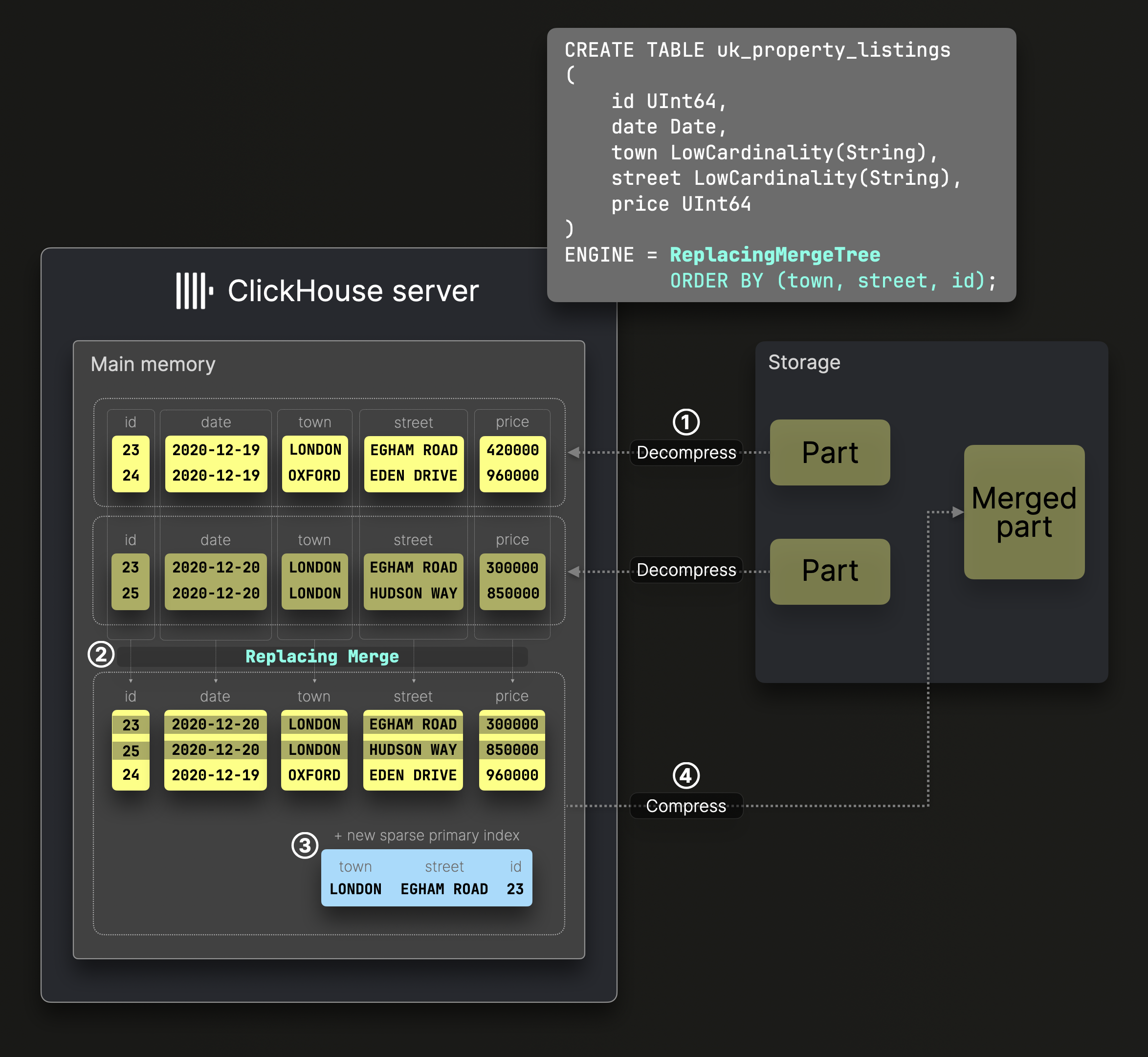
-
汇总合并
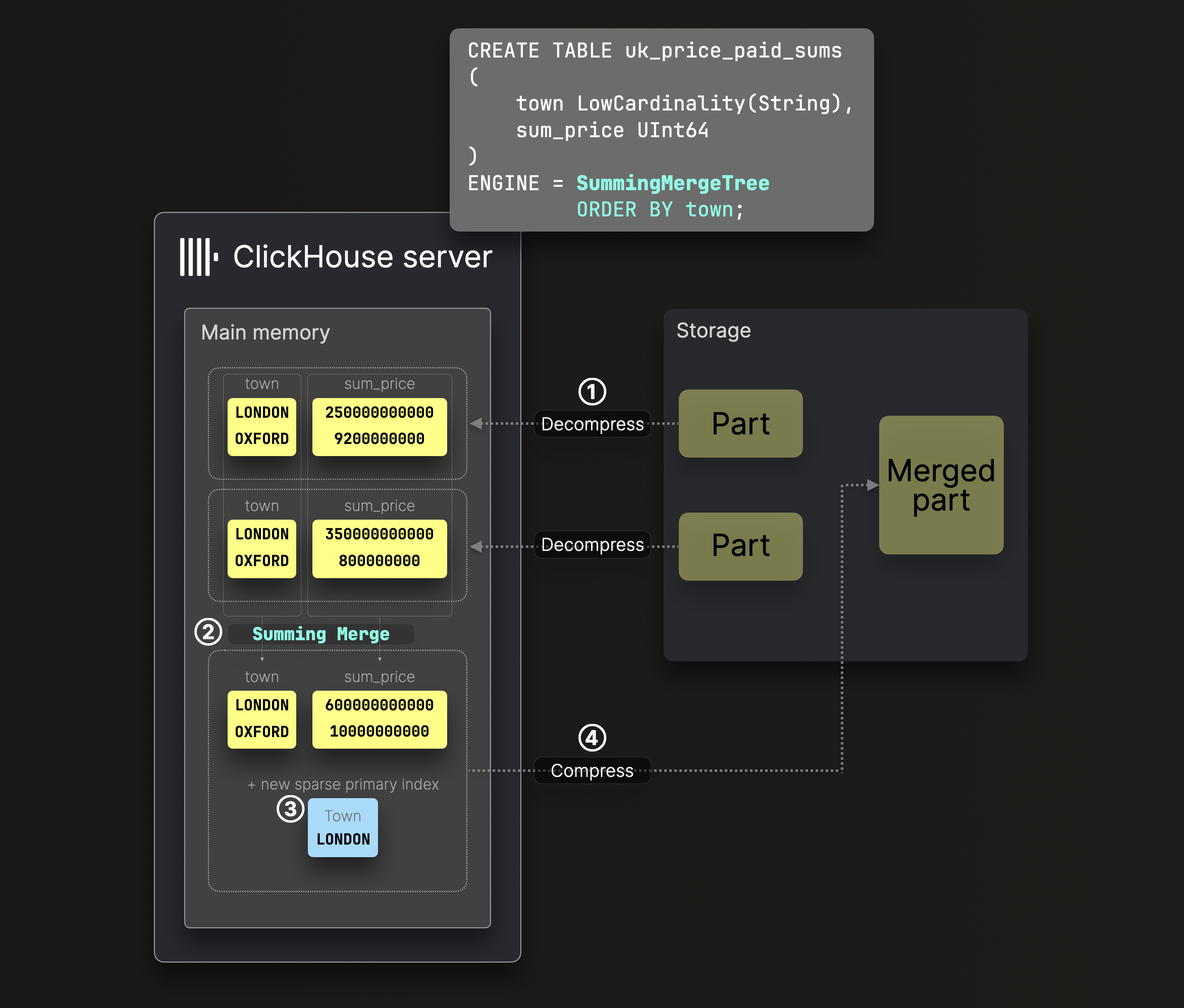
-
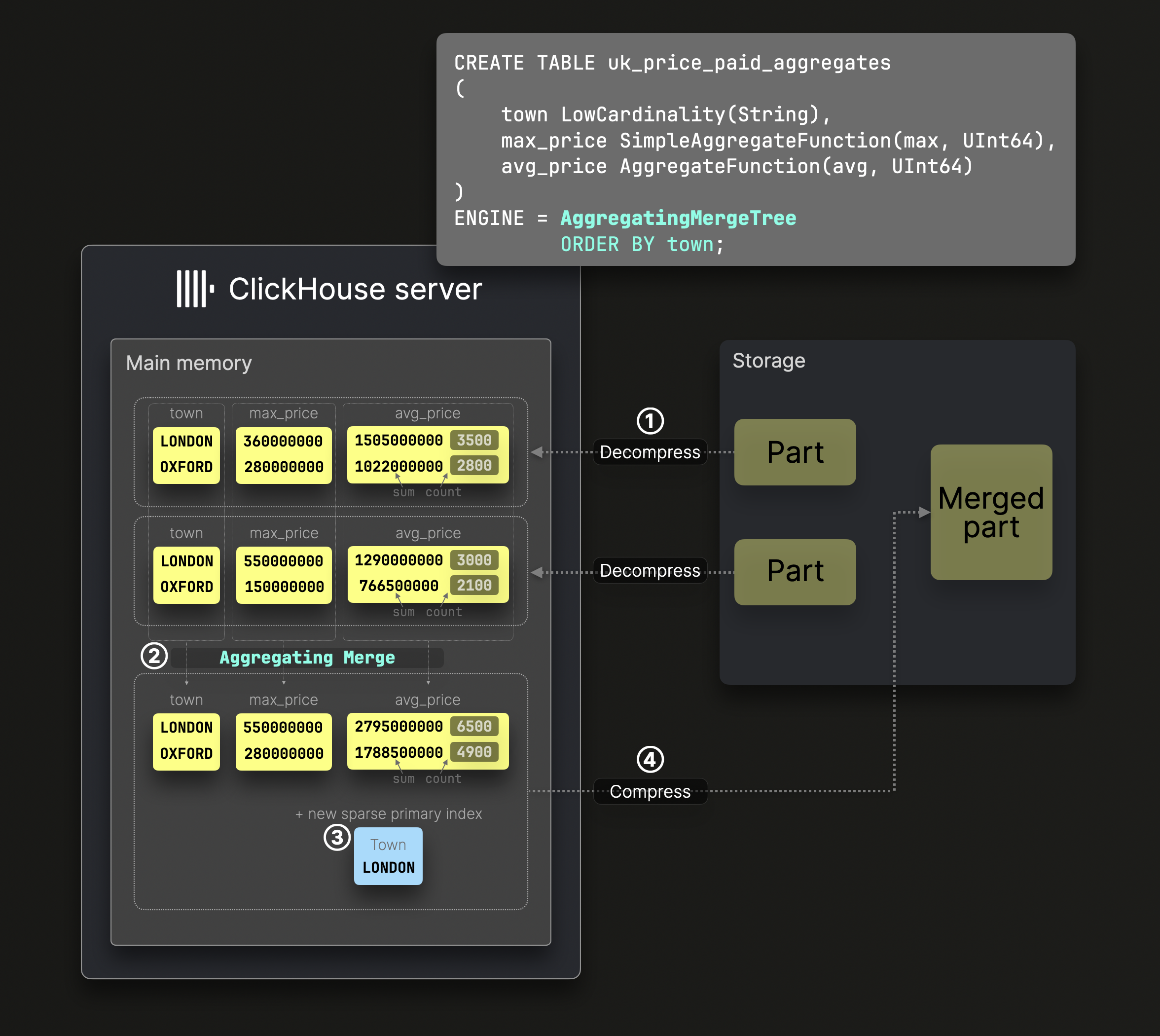
聚合合并